AWS open source newsletter, #198
A round up of the latest open source news, projects, and events that every open source developer should know about.
Ricardo Sueiras
Amazon Employee
Published May 28, 2024
Last Modified May 29, 2024
automated-datastore-discovery-with-aws-glue
containers-cost-allocation-dashboard
Demos, Samples, Solutions and Workshops
real-time-social-media-analytics-with-generative-ai
serverless-genai-food-analyzer-app
The best from around the Community
High Performance Software Foundation (HPSF)
Using Amazon Q Developer to Write Code for Observability
Welcome to issue #198 of the AWS open source newsletter, the newsletter where we try and provide you the best open source on AWS content. In this issue we feature new projects that provide integration of .NET Aspire with AWS resources, an automated data discovery tool to find data in your AWS environments, a tool to help incorporate good practices when building SaaS solutions, a cost allocation dashboard for your Kubernetes workloads, a project that might help you mitigate costs around Internet Gateway, and a few generative AI demos around food, news, and social media which you should definitely check out. Also in this edition is plenty of content on your favourite open source technologies, which this week includes Kubernetes, Leapp, OpenTelemetry, AWS CDK, llrt, Valkey, PostgreSQL, InfluxDB, High Performance Software Foundation, Karpenter, Multus, Kata, Grafana, Prometheus, Apache Flink, Zingg, Apache Hudi, Apache Iceberg, MySQL, Apache Tomcat, WordPress, AWS Amplify, Apache Airflow, OpenSearch, Apache Kafka, Bottlerocket, and Amazon EMR. As always, make sure you check out the events section at the end, and if you have your own event or online thing you want me to include here, just drop me a message.
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
aspire Provides extension methods and resources definition for a .NET Aspire AppHost to configure the AWS SDK for .NET and AWS application resources. If you are not familiar with Aspire, it is an opinionated, cloud ready stack for building observable, production ready, distributed applications in .NET. You can now use this with AWS resources, so check out the repo and the documentation that provides code examples and more.
aws-sdk-python-signers AWS SDK Python Signers provides stand-alone signing functionality. This enables users to create standardised request signatures (currently only SigV4) and apply them to common HTTP utilities like AIOHTTP, Curl, Postman, Requests and urllib3. This project is currently in an Alpha phase of development. There likely will be breakages and redesigns between minor patch versions as we collect user feedback. We strongly recommend pinning to a minor version and reviewing the changelog carefully before upgrading. Check out the README for details on how to use the signing module.
automated-datastore-discovery-with-aws-glue This sample shows you how to automate the discovery of various types of data sources in your AWS estate. Examples include - S3 Buckets, RDS databases, or DynamoDB tables. All the information is curated using AWS Glue - specifically in its Data Catalog. It also attempts to detect potential PII fields in the data sources via the Sensitive Data Detection transform in AWS Glue. This framework is useful to get a sense of all data sources in an organisation's AWS estate - from a compliance standpoint. An example of that could be GDPR Article 30. Check out the README for detailed architecture diagrams and a break down of each component as to how it works.
sbt-aws SaaS Builder Toolkit for AWS (SBT) is an open-source developer toolkit to implement SaaS best practices and increase developer velocity. It offers a high-level object-oriented abstraction to define SaaS resources on AWS imperatively using the power of modern programming languages. Using SBT’s library of infrastructure constructs, you can easily encapsulate SaaS best practices in your SaaS application, and share it without worrying about boilerplate logic. The README contains all the resources you need to get started with this project, so if you are doing anything in the SaaS space, check it out.
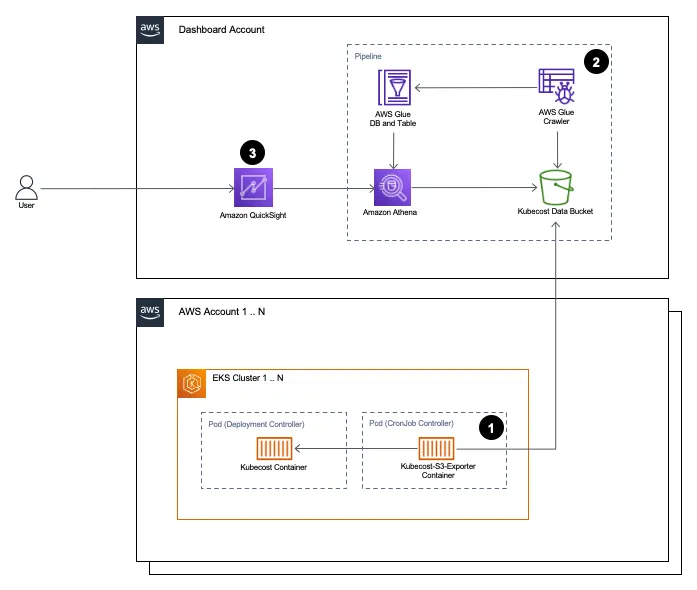
containers-cost-allocation-dashboard provides everything you need to create a QuickSight dashboard for containers cost allocation based on data from Kubecost. The dashboard provides visibility into EKS in-cluster cost and usage in a multi-cluster environment, using data from a self-hosted Kubecost pod. The README contains additional links to resources to help you understand how this works, dependencies, and how to deploy and configure this project.
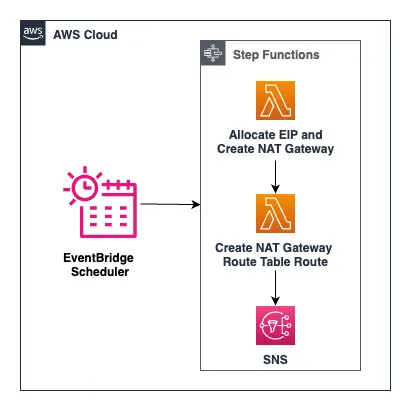
create-and-delete-ngw This project contains source code and supporting files for a serverless application that allocates an Elastic IP address, creates a NAT Gateway, and adds a route to the NAT Gateway in a VPC route table. The application also deletes the NAT Gateway and releases the Elastic IP address. The process to create and delete a NAT Gateway is orchestrated by an AWS Step Functions State Machine, triggered by an EventBridge Scheduler. The schedule can be defined by parameters during the SAM deployment process.
whats-new-summary-notifier is a demo repo that lets you build a generative AI application that summarises the content of AWS What's New and other web articles in multiple languages, and delivers the summary to Slack or Microsoft Teams.
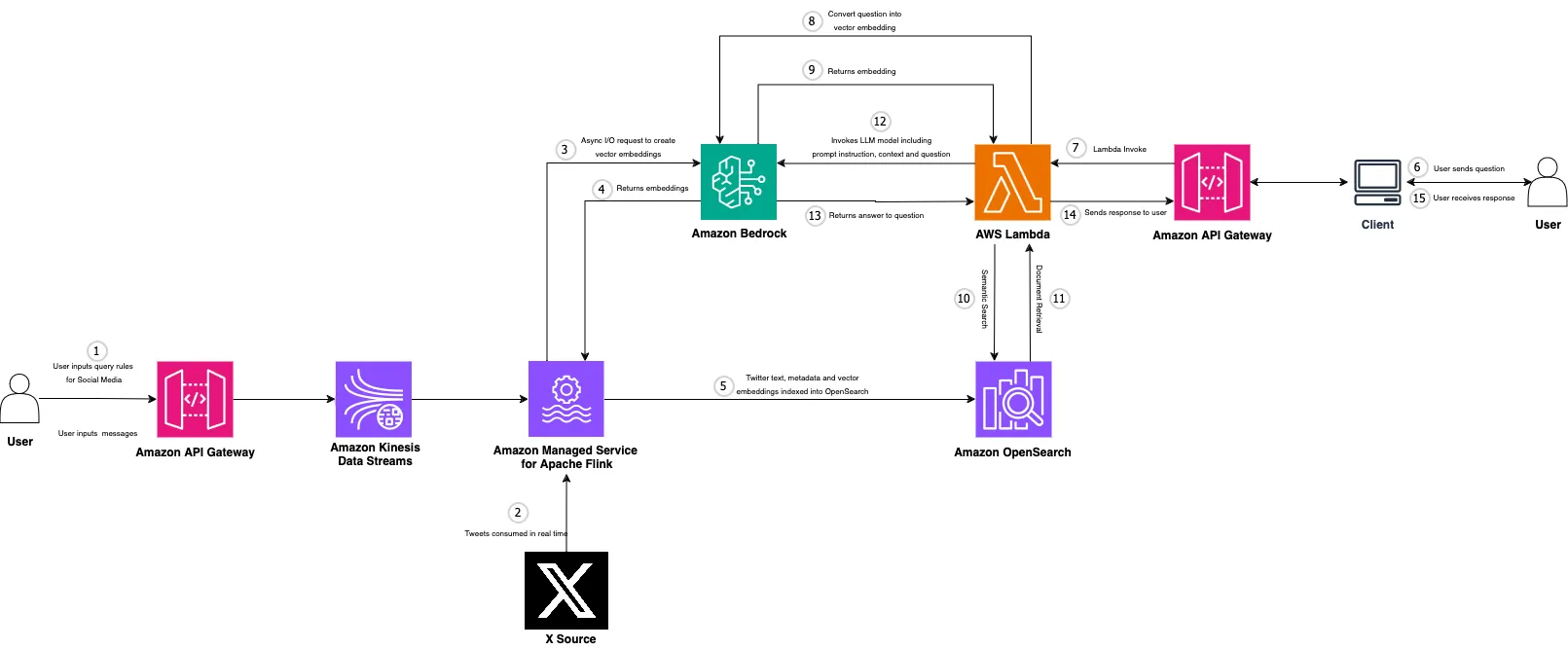
real-time-social-media-analytics-with-generative-ai this repo helps you to build and deploy an AWS Architecture that is able to combine streaming data with GenAI using Amazon Managed Service for Apache Flink and Amazon Bedrock.
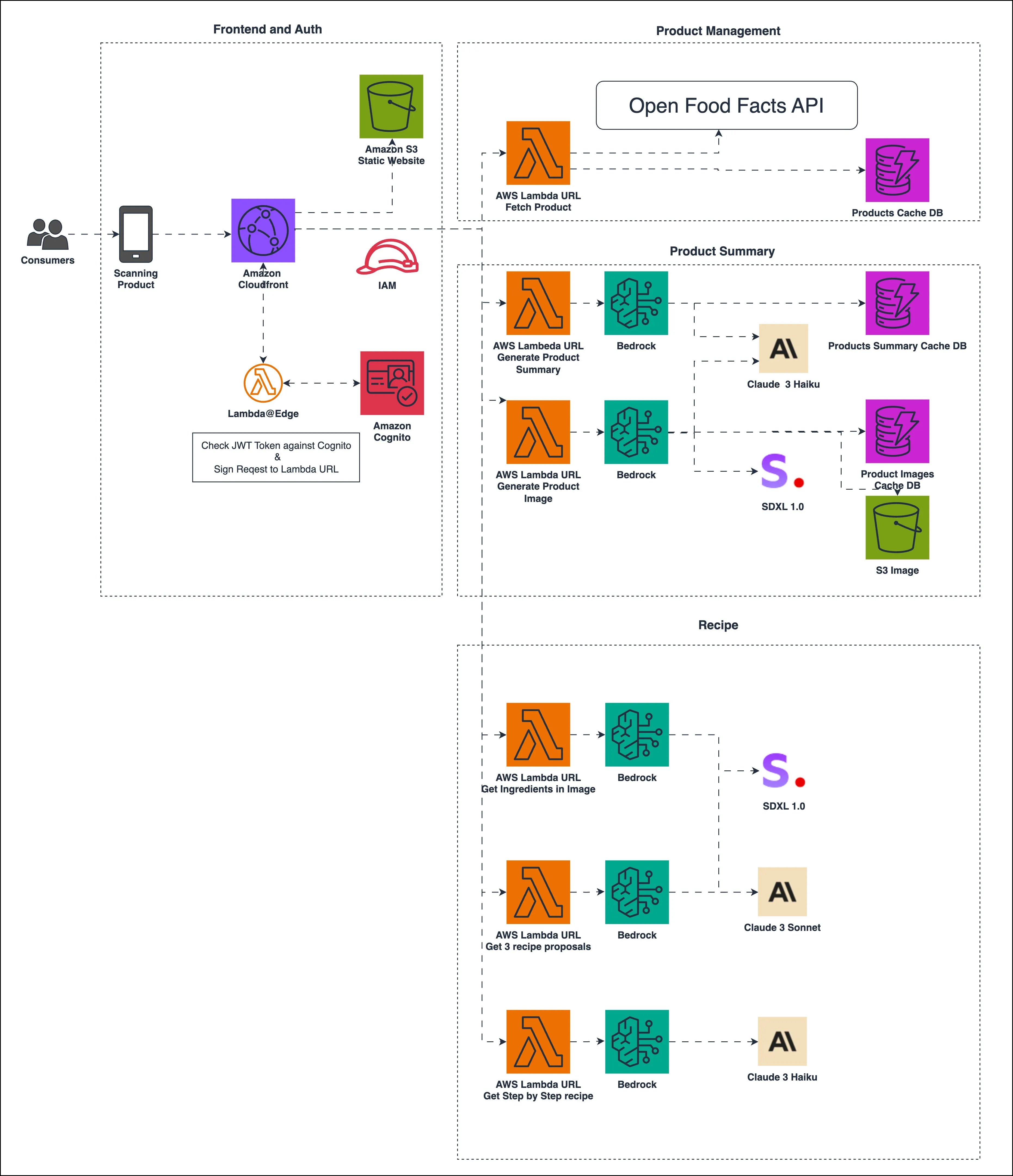
serverless-genai-food-analyzer-app provides code for a personalised GenAI nutritional web application for your shopping and cooking recipes built with serverless architecture and generative AI capabilities. It was first created as the winner of the AWS Hackathon France 2024 and then introduced as a booth exhibit at the AWS Summit Paris 2024. You use your cell phone to scan a bar code of a product to get the explanations of the ingredients and nutritional information of a grocery product personalised with your allergies and diet. You can also take a picture of food products and discover three personalised recipes based on their food preferences. The app is designed to have minimal code, be extensible, scalable, and cost-efficient. It uses Lazy Loading to reduce cost and ensure the best user experience. Tres bon!
Each week I spent a lot of time reading posts from across the AWS community on open source topics. In this section I share what personally caught my eye and interest, and I hope that many of you will also find them interesting.
Starting this off this week we have AWS Community Builder Julian Michel, who shares his personal AWS setup with you, and more importantly some of the cool open source tools you can use to keep everything in order. I use some of these myself, so make sure you check "My personal AWS account setup - IAM Identity Center, temporary credentials and sandbox account" out to see how you might be able to improve your setup.
AWS Community Builder Saifeddine Rajhi explores how to use EKS control plane logs and AWS CloudTrail logs to gain visibility into your cluster's activities, detect potential security threats, and investigate incidents in his post, "Amazon EKS: Analyze control plane and CloudTrail logs for better detective controls". Great stuff here that I will be using in the future I am sure. On a similar note, if you have ever wondered how you can export your AWS CloudWatch logs into OpenTelemetry, then AWS Community Builder Shakir provides you with some ideas in the post "Logging demo with OTEL Collector, CloudWatch and Grafana".
I am a regular user of AWS CDK, so always interested in learning how I can improve my CDK game, so enjoyed reading AWS Community Builder Peter McAree's quick post, "How to build a single-page application deployment using AWS CDK", where you will learn how to deploy a single-page application (or any other static assets) using AWS CDK.
To finish us off we go back to issue #188 of this newsletter, where I featured llrt, or Low Latency Runtime, an experimental project from awslabs that provides a lightweight JavaScript runtime designed to address the growing demand for fast and efficient Serverless applications. AWS Community Bulder Amador Criado has put together a nice lab that looks to compare how this performs compared to traditional Node.js runtimes. Grab your favourite hot beverage and then sit down to walk through, "[Lab] AWS Lambda LLRT vs Node.js".
Valkey is a continuation of open source Redis, created in response to changes to the Redis project. A number of existing contributors and maintainers of Redis formed Valkey, a new Linux Foundation project. Kyle Davis has put together How to move from Redis to Valkey, where he shows you some of the ways you can begin to make the transition.
My colleague Riccardo Ferreira also put something together for Go developers who are eager to start using Valkey in his post, Getting Started with Valkey using Docker and Go. This is a must read post this week, so make sure you check it out.
Joe Conway writes Deep PostgreSQL Thoughts: Valuing Currency where he shares his thoughts about how important it is to maintain PostgreSQL currency. Make sure you read this post that provides his views on both sides of the should I / shouldn't I question on upgrading.
More PostgreSQL content for you to check out include:
- Perform maintenance tasks and schema modifications in Amazon RDS for PostgreSQL with minimal downtime using Blue Green deployment walks you through performing schema changes and common maintenance tasks such as table and index reorganization, VACUUM FULL, and materialised view refreshes with minimal downtime using blue/green deployments for an Amazon Relational Database (Amazon RDS) for PostgreSQL database or an Amazon Aurora PostgreSQL-Compatible Edition cluster [hands on]
- PostgreSQL for SaaS on AWS provides a collection of best practices for running PostgreSQL workloads for SaaS applications on AWS
In the post, Introducing Amazon Timestream for InfluxDB: A managed service for the popular open source time-series database, Victor Servin provides an overview of the recently launched Amazon Timestream for InfluxDB, our latest managed time-series database engine for customers who want open source APIs and real-time, time-series applications. Read the post to find out more why this AWS has created this service.
In case you missed the announcement a week or so ago, Brendan Bouffler has put together a blog post, Announcing the High Performance Software Foundation (HPSF), where he shares more info about the new High Performance Software Foundation (HPSF), including how it can help, what they are currently doing as they bootstrap, and how you can get involved.
- Deploying Karpenter Nodes with Multus on Amazon EKS shows how Karpenter can be used in conjunction with Multus CNI, a container network interface (CNI) plugin for Kubernetes that enables attaching multiple network interfaces to pods [hands on]
- Ensuring fair bandwidth allocation for Amazon EKS Workloads provides a hands on guide on how you can use the Amazon VPC CNI plugin and its capabilities to limit ingress and egress bandwidth for applications running as pods in Amazon EKS [hands on]
- How to automate application log ingestion from Amazon EKS on Fargate into AWS CloudTrail Lake looks at how to capture the STDOUT and STDERR input/output (I/O) streams from your container and send them to S3 using Fluent Bit [hands on]
- Enhancing Kubernetes workload isolation and security using Kata Containers details the process of setting up a self-managed microVM infrastructure on Amazon EKS by using Amazon EC2 bare metal instances and Kata Containers [hands on]
- Enhancing observability with a managed monitoring solution for Amazon EKS walks you through a solution that provides monitoring Amazon EKS clusters with Amazon Managed Grafana and Amazon Managed Service for Prometheus [hands on]
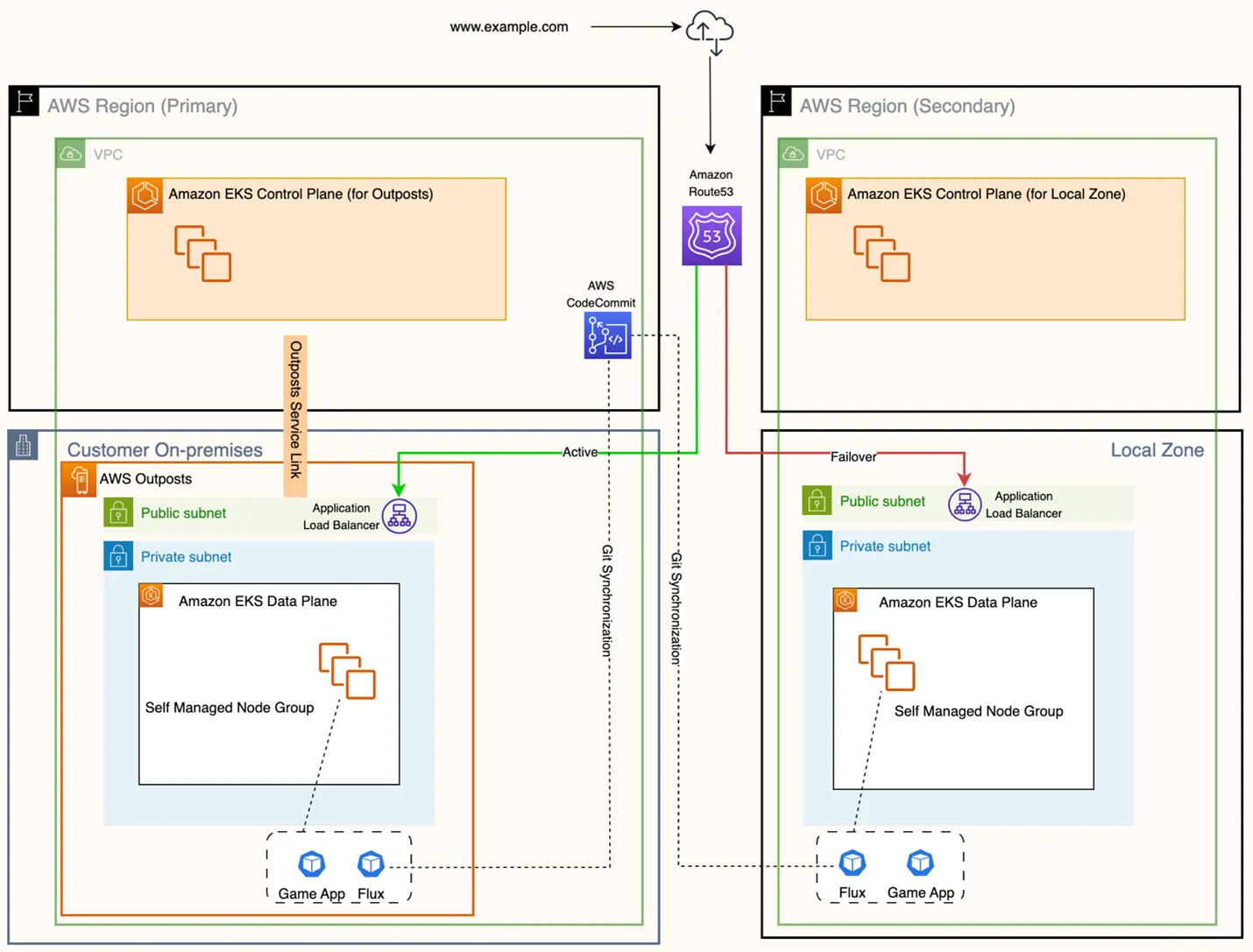
- Disaster Recovery on AWS Outposts to AWS Local Zones with a GitOps approach for Amazon EKS is a great overview of how AWS Local Zones can be used as a DR option for Amazon EKS workloads running on AWS Outposts [hands on]
- Multi-Region Disaster Recovery with Amazon EKS and Amazon EFS for Stateful workloads takes a look at how to achieve business continuity in AWS by using Amazon EFS and Amazon EKS across AWS Regions [hands on]
- Unleash the possibilities of Stable Diffusion helps you understand your options when it comes to deploying Stable Diffusion on open source technologies on AWS [hands on]
- In-place version upgrades for applications on Amazon Managed Service for Apache Flink now supported explores in-place version upgrades, a new feature offered by Managed Service for Apache Flink, covering how to get started, insights into the feature, and a deeper dive into how the feature works and some sample use cases [hands on]
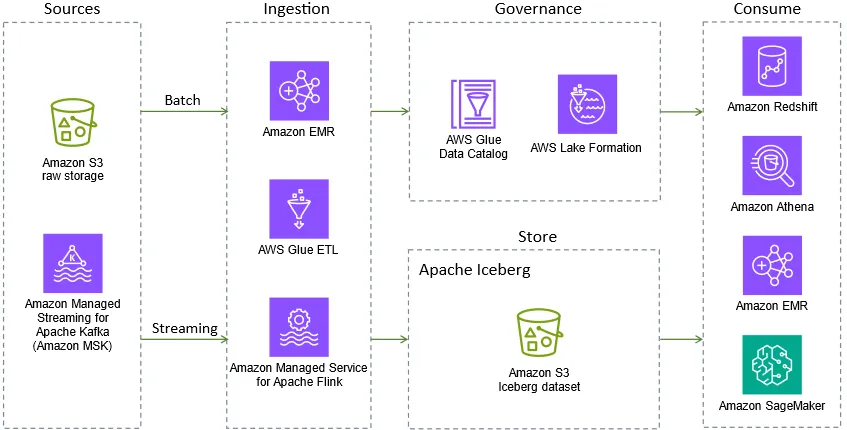
- Entity resolution and fuzzy matches in AWS Glue using the Zingg open source librarylooks at how to use Zingg, an open source library specifically designed for entity resolution on Spark, to help address data governance challenges and provide consistent and accurate data across your organisation [hands on]
- Use AWS Data Exchange to seamlessly share Apache Hudi datasets shows how you can take advantage of the data sharing capabilities in AWS Data Exchange on top of Apache Hudi [hands on]
- Understanding Apache Iceberg on AWS with the new technical guide announces the launch of the Apache Iceberg on AWS technical guide, a comprehensive technical guide that offers detailed guidance on foundational concepts to advanced optimisations to build your transactional data lake with Apache Iceberg on AWS
- Binary logging optimizations in Amazon Aurora MySQL version 3 discusses use cases for binary logging in Amazon Aurora MySQL, improved binary logging capabilities that have been added to Amazon Aurora MySQL over the years, and additional support for MySQL native binary logging features
- Integrate Amazon Aurora MySQL and Amazon Bedrock using SQL is a must read to see how you can invoke foundational models on Amazon Bedrock as SQL functions on Amazon Aurora MySQL [hands on]
- Monitor Java apps running on Tomcat server with Amazon CloudWatch Application Signals (Preview) demonstrates how to auto-instrument Java web applications deployed via WAR packages and running on Tomcat server with AWS Distro for OpenTelemetry (ADOT), using CloudWatch Application Signals (Preview) [hands on]
- New in AWS Amplify: Integrate with SQL databases, OIDC/SAML providers, and the AWS CDK provides a glimpse of how you can extend your AWS Amplify project, using three examples how you can integrate with existing data sources, authenticate with any OpenID Connect or SAML authentication provider, and customise the AWS Amplify generated resources through CDK [hands on]
- A Pilot Light disaster recovery strategy for WordPress dives into how you can architect a resilient cross-Region Pilot Light DR strategy for WordPress, that uses the robust global infrastructure of AWS
Amazon Managed Workflows for Apache Airflow (MWAA) is a managed orchestration service for Apache Airflow that makes it easier to set up and operate end-to-end data pipelines in the cloud. FIPS compliant endpoints on Amazon MWAA helps companies contracting with the US and Canadian federal governments meet the FIPS security requirement to encrypt sensitive data in supported Regions. Amazon MWAA now offers Federal Information Processing Standard (FIPS) 140-2 validated endpoints to help you protect sensitive information. These endpoints terminate Transport Layer Security (TLS) sessions using a FIPS 140-2 validated cryptographic software module, making it easier for you to use Amazon MWAA for regulated workloads.
In addition to this, a long awaited ask by Apache Airflows users is now available. Amazon MWAA now supports the Airflow REST API along with web server auto scaling, allowing customers to programmatically monitor and manage their Apache Airflow environments at scale. With Airflow REST API support, customers can now monitor workflows, trigger new executions, manage connections, and perform other administration tasks with ease via scalable API calls. Web server auto scaling enables MWAA to automatically scale out the Airflow web servers to handle increased demand, whether from REST API requests, Command Line Interface (CLI) usage, or more concurrent Airflow User Interface (UI) users.
Check out the post, Introducing Amazon MWAA support for the Airflow REST API and web server auto scaling, to dive deeper into this, and get a hands on guide on how to get started with using the Airflow REST API and web server auto scaling on Amazon MWAA.
You can now run OpenSearch version 2.13 in Amazon OpenSearch Service. With OpenSearch 2.13, we have made several improvements to search performance and resiliency, OpenSearch Dashboards, and added new features to help you build AI-powered applications. We have introduced concurrent segment search that allows users to query index segments in parallel at the shard level. This offers improved latency for long-running requests that contain aggregations or large ranges. You can now index quantised vectors with FAISS-engine-based k-NN indexes, with potential to reduce memory footprint by as much as 50 percent with minimal impact to accuracy and latency. I/O-based admission control proactively monitors and prevents I/O usage breaches to further improve the resilience of the cluster.
This launch also introduces several features that enable you to build and deploy AI-powered search applications. The new flow framework, helps you to automate the configuration of search and ingest pipeline resources required by advanced search features like semantic, multimodal, and conversational search. This adds to existing capabilities for automating ml-commons resource setup, allowing you to package OpenSearch AI solutions into portable templates. Additionally, we’ve added predefined templates to automate setup for models that are integrated through our connectors to APIs like OpenAI, Amazon Bedrock, and Cohere that enable you to build solutions like semantic search.
Amazon Relational Database Service (RDS) for PostgreSQL announces Amazon RDS Extended Support minor version 11.22-RDS.20240418. We recommend that you upgrade to this version to fix known security vulnerabilities and bugs in prior versions of PostgreSQL. Amazon RDS Extended Support provides you more time, up to three years, to upgrade to a new major version to help you meet your business requirements. During Extended Support, Amazon RDS will provide critical security and bug fixes for your MySQL and PostgreSQL databases on Aurora and RDS after the community ends support for a major version. You can run your PostgreSQL databases on Amazon RDS with Extended Support for up to three years beyond a major version’s end of standard support date.
Amazon RDS for PostgreSQL now supports pgvector 0.7.0, an open-source extension for PostgreSQL for storing vector embeddings in your database, letting you use retrieval-augemented generation (RAG) when building your generative AI applications. This release of pgvector includes features that increase the number of dimensions of vectors you can index, reduce index size, and includes additional support for using CPU SIMD in distance computations. pgvector 0.7.0 adds two new vector data types: halfvec for storing dimensions as 2-byte floats, and sparsevec for storing up to 1,000 nonzero dimensions, and now supports indexing binary vectors using the PostgreSQL-native bit type. These additions let you use scalar and binary quantization for the vector data type using PostgreSQL expression indexes, which reduces the storage size of the index and lowers the index build time. Quantization lets you increase the maximum dimensions of vectors you can index: 4,000 for halfvec and 64,000 for binary vectors. pgvector 0.7.0 also adds functions to calculate both Hamming and Jaccard distance for binary vectors. pgvector 0.7.0 is available on database instances in Amazon RDS running PostgreSQL 16.3 and higher, 15.7 and higher, 14.12 and higher, 13.15 and higher, and 12.19 and higher in all applicable AWS Regions, including the AWS GovCloud (US) Regions.
Amazon Relational Database Service (RDS) for MySQL announced Amazon RDS Extended Support for minor version 5.7.44-RDS.20240408. We recommend that you upgrade to this version to fix known security vulnerabilities and bugs in prior versions of MySQL. Amazon RDS Extended Support provides you more time, up to three years, to upgrade to a new major version to help you meet your business requirements. During Extended Support, Amazon RDS will provide critical security and bug fixes for your MySQL and PostgreSQL databases on Aurora and RDS after the community ends support for a major version. You can run your MySQL databases on Amazon RDS with Extended Support for up to three years beyond a major version’s end of standard support date.
Amazon Managed Streaming for Apache Kafka (Amazon MSK) now supports removing brokers from MSK provisioned clusters. Administrators can optimise costs of their Amazon MSK clusters by reducing broker count to meet the changing needs of their streaming workloads, while maintaining cluster performance, availability, and data durability. Customers use Amazon MSK as the core foundation to build a variety of real-time streaming applications and high-performance event driven architectures. As their business needs and traffic patterns change, they often adjust their cluster capacity to optimise their costs. Amazon MSK Provisioned provides flexibility for customers to change their provisioned clusters by adding brokers or changing the instance size and type. With broker removal, Amazon MSK Provisioned now offers an additional option to right-size cluster capacity. Customers can remove multiple brokers from their MSK provisioned clusters to meet the varying needs of their streaming workloads without any impact to client connectivity for reads and writes. By using broker removal capability, administrators can adjust cluster’s capacity, eliminating the need to migrate to another cluster to reduce broker count.
You can dive deeper into this by checking out the blog post, Safely remove Kafka brokers from Amazon MSK provisioned clusters
Bottlerocket, the Linux-based operating system purpose-built for containers, now supports NVIDIA Fabric Manager, enabling users to harness the power of multi-GPU configurations for their AI and machine learning workloads. With this integration, Bottlerocket users can now seamlessly leverage their connected GPUs as a high-performance compute fabric, enabling efficient and low-latency communication between all the GPUs in each of their P4/P5 instances. The growing sophistication of deep learning models has led to an exponential increase in the computational resources required to train them within a reasonable timeframe. To address this increase in computational demands, customers running AI and machine learning workloads have turned to multi-GPU implementations, leveraging NVIDIA's NVSwitch and NVLink technologies to create a unified memory fabric across connected GPUs. The Fabric Manager support in the Bottlerocket NVIDIA variants allows users to configure this fabric, enabling all GPUs to be used as a single, high-performance pool rather than individual units. This unlocks Bottlerocket users to run multi-GPU setups on P4/P5 instances, significantly accelerating the training of complex neural networks.
Amazon Managed Service for Prometheus now supports inline editing of rules and alert manager configuration directly from the AWS console. Amazon Managed Service for Prometheus is a fully managed Prometheus-compatible monitoring service that makes it easy to monitor and alarm on operational metrics at scale. Prometheus is a popular Cloud Native Computing Foundation open-source project for monitoring and alerting on metrics from compute environments such as Amazon Elastic Kubernetes Service. Previously, customers could define alerting and recording rules, or alert manager definition, by importing respective configuration defined in a YAML file, via the AWS console. Now, they can import, preview, and edit existing rules or alert manager configurations from YAML files or create them directly from the AWS console. The inline editing experience allows customers to preview their rules and alert manager configuration prior to setting them.
Amazon Managed Service for Prometheus collector, a fully-managed agent-less collector for Prometheus metrics, now integrates with the Amazon EKS access management controls. Starting today, the collector utilises the EKS access management controls to create a managed access policy that allows the collector to discover and collect Prometheus metrics. Amazon Managed Service for Prometheus collector with support for EKS access management controls is available in all regions where Amazon Managed Service for Prometheus is available.
Customers can now run Amazon Managed Grafana workspaces with Grafana version 10.4. This release includes features that were launched as a part of open source Grafana versions 9.5 to 10.4, including Correlations, Subfolders, and new visualisation panels such as Data Grid, XY chart and Trend panel. This release also introduces new configuration APIs to manage service accounts and tokens for Amazon Managed Grafana workspaces. Service Accounts, replace API keys as the primary way to authenticate applications with Grafana APIs using Service Account Tokens. These new APIs eliminate the need to manually create Service accounts, enabling customers to fully automate their provisioning workflows. With correlations, customers can define relationships between different data sources, rendered as interactive links in Explore visualisations that trigger queries on the related data source; carrying forward data like namespace, host, or label values, enabling root cause analysis with a diverse set of data sources. Subfolders enable nested hierarchy of folders with nested layers of permissions, allowing customers to organise their dashboards to reflect their organisation’s hierarchy. To explore the complete list of new features, please refer to our user documentation. Grafana version 10.4 is supported in all AWS regions where Amazon Managed Grafana is generally available.
Check out more details in the post, Amazon Managed Grafana announces support for Grafana version 10.4
You can now use CoreDNS autoscaling capabilities for Amazon EKS clusters. This feature allows you to scale capacity of DNS server instances to meet the ever-changing capacity needs of your services without the overhead of managing custom solutions. Organisations are standardising on Kubernetes as their compute infrastructure platform to build scalable, containerised applications. Scaling CoreDNS Pods is key to ensure reliable DNS resolution by distributing the query load across multiple instances, and provide high availability for applications and services. With this launch, you no longer need to pre-configure the scaling parameters and deploy a client on each cluster to monitor the capacity and scale accordingly. EKS manages the autoscaling of DNS resources when you use the CoreDNS EKS add-on. This feature works for CoreDNS v1.9 and EKS release version 1.25 and later.
Amazon EMR provides big data solutions for petabyte-scale data processing, interactive analytics, and machine learning using open-source frameworks such as Apache Spark, Apache Hive, and Presto. Today, we are excited to announce that Amazon EMR 7.1 release is now generally available and includes the latest versions of popular open-source software. Amazon EMR 7.1 includes Trino 435, PrestoDB 0.284, Apache Zookeeper 3.9.1, Apache Livy 0.8, Apache Flink 1.18.1, Apache Hudi 0.14.1, and Apache Iceberg 1.4.3. In addition, Amazon EMR 7.1 introduces support for Python 3.11 for Apache Spark 3.5 applications.
In addition to this, Amazon EMR 7.1 introduced the capability to configure Amazon CloudWatch Agent to publish additional metrics for Apache Hadoop, YARN, and Apache HBase applications running on your Amazon EMR on EC2 clusters. This feature provides comprehensive monitoring capabilities, allowing you to track the performance and health of your cluster more effectively. Amazon EMR automatically publishes a set of free metrics every five minutes for monitoring cluster activity and health. Starting with Amazon EMR Release 7.0, you can install the Amazon CloudWatch Agent to publish 34 paid metrics to Amazon CloudWatch every minute. With Amazon EMR 7.1, you can now configure the agent to send additional paid metrics, providing even deeper visibility into your cluster's performance. Furthermore, you can opt to send these metrics to an Amazon Managed Service for Prometheus endpoint, if you are already using Prometheus to monitor your enterprise metrics. Additional metrics are is available with Amazon EMR release 7.1, in all regions where Amazon EMR is available.
Love this video from Ricardo Ferreira that shows how you can use tools like Amazon Q Developer to help you integrate open source libraries like OpenTelemetry into your existing applications. In this video, Ricardo shows how to use Amazon Q Developer to instrument a micro service written in Go for OpenTelemetry.
If you are planning any events in 2024, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
FOSS in Flux: Redis Relicensing and the Future of Open Source May 28th, 16:00CET/10:00amET YouTube
With all the recent cases of open source projects shifting away from their roots, topped with the recent Redis relicensing, your host Dotan Horovits and David Nalley from AWS take to look into the state of FOSS (free and open source software).
BSides Exeter July 27th, Exeter University, UK
Looking forward to joining the community at BSides Exeter to talk about one of my favourite open source projects, Cedar. Check out the event page and if you are in the area, come along and learn about Cedar and more!
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Ricardo Ferreira, David Nalley, Dotan Horovits, Mansi Bhutada, Kamen Sharlandjiev, Kartikay Khator, Jeremy Ber, Chris Dziolak, Gonzalo Herreros, Emilio Garcia Montano, Noritaka Sekiyama, Rolando Jr Hilvano, Ashutosh Tulsi, Young Jung, Neb Miljanovic, Sudhir Shet, Saurabh Bhutyani, Ankith Ede, Chandra Krishnan, Joe Conway, Sebastian Lee, Natavit Rojcharoenpreeda, Yee Fei Ooi, Victor Servin, Carlos Rodrigues, Imtiaz Sayed, Shana Schipers, Marc Reilly, Jegan Sundarapandian, Mirash Gjolaj, Re Alvarez-Parmar, Vidhi Taneja, Anusha Dasarakothapalli, Masudur Rahaman Sayem,Rodrigue Koffi, Dan Malloy, Priyanka Verma, Siva Guruvareddiar, Michael Hausenblas, Jay Joshi, Deep Chhaiya, Samir Khan, Insoo Jang, Matt Price, Anita Singh, Nathan Ballance, Baji Shaik, Sarabjeet Singh, Dumlu Timuralp, Eric Heinrichs, Steve Dille, Shinya Sugiyama, Rene Brandel, Tinotenda Chemvura, Benjamin Le, Josh, Amador Criado, Peter McAree, Saifeddine Rajhi, Shakir, and Julian Michel.
Feedback
Please please please take 1 minute to complete this short survey.
Remember to check out the Open Source homepage for more open source goodness.
One of the pieces of feedback I received in 2023 was to create a repo where all the projects featured in this newsletter are listed. Where I can hear you all ask? Well as you ask so nicely, you can meander over to newsletter-oss-projects.
Made with ♥ from DevRel
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.