
Build Document Processing Pipelines with Project Lakechain
Learn how to create cloud-native, AI-powered document processing pipelines on AWS with Project Lakechain.
João Galego
Amazon Employee
Published Jun 25, 2024
Last Modified Jun 26, 2024
In this post, we're going to explore Project Lakechain: a cool, new project from AWS Labs for creating modern, AI-powered, document processing pipelines.
Based on the AWS Cloud Development Kit (CDK), it provides
60+ ready-to-use components for processing images 🖼️, text 📄, audio 🔊 and video 🎞️, as well as integration with Generative AI services like Amazon Bedrock and vector stores like Amazon OpenSearch or LanceDB.The greatest thing about Project Lakechain (documentation is a close second!) is how easy it is to combine these components into complex processing pipelines that can scale out of the box to millions of documents... using only infrastructure as code (IaC).
But don't just take my word for it... let me show you how it actually works!
Image not found
Before we get started, make sure these tools are installed and properly configured:
- AWS CLI ☁️
- Docker 🐋
- TypeScript
5.0+(optional) - AWS CDK v2 (optional)
For more information, please check the Prerequisites section of the Lakechain docs.
The only thing you need to do to set up Lakechain is to clone the repository
1
2
git clone https://github.com/awslabs/project-lakechain
cd project-lakechainand install the project dependencies
1
npm installAt this point, you can either try one of the simple pipelines or, if you're feeling brave enough, one of the end-to-end use cases.
💡 The Quickstart section is an excellent place to start. It will guide you through the deployment of a face detection pipeline using AWS Rekognition.

Adapted from the Content Moderation Immersion Day workshop. Check it out!
Learning about a new framework is all about understanding the problems it tries to solve.
Sticking close to this philosophy, let's try to build a pipeline from scratch to get some hands-on experience.
💡 In this blog, I will not cover the basics of the AWS CDK. If you need a refresher on on how to work with the AWS CDK in TypeScript or some other topic, just head over to the AWS CDK Developer Guide.
We'll go for something simple: the Quickstart pipeline is about image moderation 🧑🦰🛑, so let's try to create a similar one for text 📄🛑.
In good Mermaid style, our pipeline will look something like this:
1
2
3
4
5
6
7
8
flowchart LR
Input([Input Bucket]) -.-> S3[S3 Trigger]
S3 -. Document .-> Comprehend[NLP Text Processor]
Comprehend --> PiiCondition{Contains PII Information?}
PiiCondition -- Yes --> Moderated[Moderated S3 Bucket]
PiiCondition -- No --> SentimentCondition{Non-Negative Sentiment?}
SentimentCondition -- No --> Moderated
SentimentCondition -- Yes --> Safe[Safe S3 Bucket]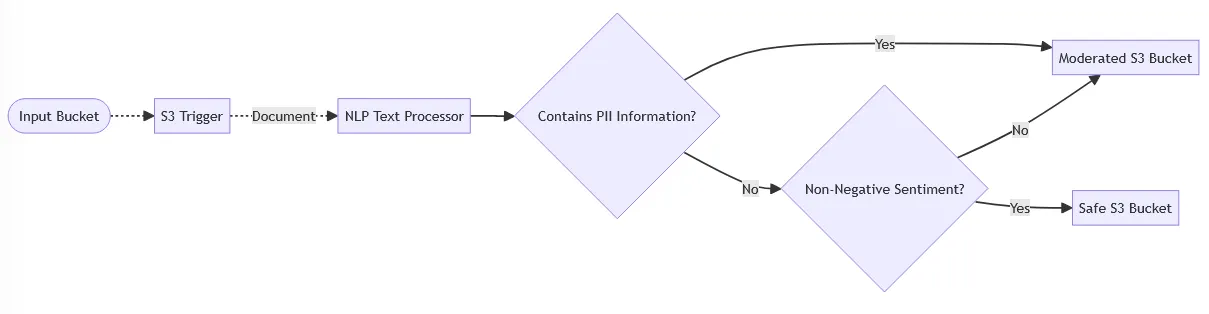
Here's how it works:
- 🔫 The pipeline is triggered every time we upload a file to the
Input Bucket. - 🗣️ It then calls the NLP processor, which is powered by Amazon Comprehend, to determine the dominant language, perform sentiment analysis and detect personally identifiable information (PII).
- ✅ The text is sent to the
Safe Bucketif it doesn't contain PII data and has non-negative sentiment. - ⛔ Otherwise, it is placed in the
Moderated Bucketso it can be checked by a human reviewer.
If you're of the just-show-me-the-code persuasion, here's our text moderation stack in full:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
// stack.ts
import * as cdk from 'aws-cdk-lib';
import * as s3 from 'aws-cdk-lib/aws-s3';
import { Construct } from 'constructs';
import { CacheStorage } from '@project-lakechain/core';
import { Condition, CloudEvent } from '@project-lakechain/condition';
import { S3EventTrigger } from '@project-lakechain/s3-event-trigger';
import { NlpTextProcessor, dsl as l } from '@project-lakechain/nlp-text-processor';
import { S3StorageConnector } from '@project-lakechain/s3-storage-connector';
import { TextMetadata } from '@project-lakechain/sdk/models/document/metadata';
/**
* Example stack for moderating documents in a pipeline.
* The pipeline looks as follows:
*
* ┌──────────────┐ ┌─────────────────┐ ┌──────┐
* │ S3 Input ├──►│ NLP Processor ├──►| S3 │
* └──────────────┘ └─────────────────┘ └──────┘
*
*/
export class TextModerationPipeline extends cdk.Stack {
/**
* Stack constructor.
*/
constructor(scope: Construct, id: string, env: cdk.StackProps) {
super(scope, id, {
description: 'A pipeline demonstrating how to use Amazon Comprehend for text moderation.',
...env
});
///////////////////////////////////////////
/////// S3 Storage ///////
///////////////////////////////////////////
// The source bucket.
const source = new s3.Bucket(this, 'Bucket', {
encryption: s3.BucketEncryption.S3_MANAGED,
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
autoDeleteObjects: true,
removalPolicy: cdk.RemovalPolicy.DESTROY,
enforceSSL: true
});
// The moderated texts bucket.
const moderated = new s3.Bucket(this, 'Moderated', {
encryption: s3.BucketEncryption.S3_MANAGED,
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
autoDeleteObjects: true,
removalPolicy: cdk.RemovalPolicy.DESTROY,
enforceSSL: true
});
// The safe texts bucket.
const safe = new s3.Bucket(this, 'Safe', {
encryption: s3.BucketEncryption.S3_MANAGED,
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
autoDeleteObjects: true,
removalPolicy: cdk.RemovalPolicy.DESTROY,
enforceSSL: true
});
// The cache storage.
const cache = new CacheStorage(this, 'Cache', {});
///////////////////////////////////////////
/////// Lakechain Pipeline ///////
///////////////////////////////////////////
// Monitor a bucket for uploaded objects.
const trigger = new S3EventTrigger.Builder()
.withScope(this)
.withIdentifier('Trigger')
.withCacheStorage(cache)
.withBucket(source)
.build();
// The NLP text process will identify PII information
// and perform sentiment analysis
const nlpProcessor = new NlpTextProcessor.Builder()
.withScope(this)
.withIdentifier('NlpTextProcessor')
.withCacheStorage(cache)
.withSource(trigger)
.withIntent(
l.nlp()
.language()
.sentiment()
.pii(l.confidence(90))
)
.build()
const condition = new Condition.Builder()
.withScope(this)
.withIdentifier('Condition')
.withCacheStorage(cache)
.withSource(nlpProcessor)
.withConditional(async (event: CloudEvent) => {
const metadata = event.data().metadata();
const attrs = metadata.properties?.attrs as TextMetadata;
const piis = attrs.stats?.piis;
const sentiment = attrs.sentiment;
const has_pii = piis != 0;
const non_negative_sentiment = sentiment == "positive" || sentiment == "neutral";
return !has_pii && non_negative_sentiment;
})
.build();
// Writes the results to the moderated bucket when
// PII labels exist in the document metadata and the
// sentiment is not positive
condition.onMismatch(
new S3StorageConnector.Builder()
.withScope(this)
.withIdentifier('ModeratedStorage')
.withCacheStorage(cache)
.withDestinationBucket(moderated)
.build()
);
// Writes the results to the safe bucket when PII
// labels do not exist in the document metadata and
// the sentiment is positive
condition.onMatch(
new S3StorageConnector.Builder()
.withScope(this)
.withIdentifier('SafeStorage')
.withCacheStorage(cache)
.withDestinationBucket(safe)
.build()
);
// Display the source bucket information in the console.
new cdk.CfnOutput(this, 'SourceBucketName', {
description: 'The name of the source bucket.',
value: source.bucketName
});
// Display the moderated bucket information in the console.
new cdk.CfnOutput(this, 'ModeratedBucketName', {
description: 'The name of the bucket containing moderated documents.',
value: moderated.bucketName
});
// Display the safe bucket information in the console.
new cdk.CfnOutput(this, 'SafeBucketName', {
description: 'The name of the bucket containing safe documents.',
value: safe.bucketName
});
}
}
// Creating the CDK application.
const app = new cdk.App();
// Environment variables.
const account = process.env.CDK_DEFAULT_ACCOUNT ?? process.env.AWS_DEFAULT_ACCOUNT;
const region = process.env.CDK_DEFAULT_REGION ?? process.env.AWS_DEFAULT_REGION;
// Deploy the stack.
new TextModerationPipeline(app, 'TextModerationPipeline', {
env: {
account,
region
}
});
✨ Good news, everyone! There's no need to create a new stack since the latest version of the code already contains an implementation of the text moderation pipeline.
In the Project Lakechain repo, just head over to the text moderation pipeline directory
1
cd examples/simple-pipelines/text-moderation-pipelineand run the following commands to build it
1
2
npm install
npm run build-pkgOnce you've configured the AWS credentials and the target region, you can deploy the example to your account
1
npm run deployImage not found
You can use the AWS CloudWatch Logs console to live tail the log groups associated with the deployed middlewares to see the logs in real-time:
Image not found
Let's try to upload a file (Little Red Riding Hood 👧🔴👵🐺) to the
Input Bucket and see what happens:Image not found
After a couple of seconds, the file as well as some metadata will be added to the
Safe BucketImage not found
In the metadata file, we can see that the dominant language is English 💂, the sentiment
NEUTRAL 😐 and that Amazon Comprehend has found no PII data 👤.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
(...)
"metadata": {
"custom": {
"__condition_result": "true"
},
"language": "en",
"properties": {
"attrs": {
"pii": "s3://textmoderationpipeline-cachestorageXXXXX-XXXXX/nlp-text-processor/XXXXX",
"sentiment": "neutral",
"stats": {
"piis": 0
}
},
"kind": "text"
}
}
(...)☝️ Feel free to try other documents and don't forget to clean up everything when you're done
1
npm run destroySee you next time! 👋
Image not found
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.
5 Comments
Log in to comment