Deploy Your Web Application with AWS Elastic Beanstalk and AWS CDK Pipelines
A walk-through of deploying a web application using AWS Elastic Beanstalk and AWS CDK Pipelines to streamline the development process with best practices like versioning, change tracking, code review, testing, and rollbacks.
Rohini Gaonkar
Amazon Employee
Published Apr 10, 2023
Last Modified Mar 19, 2024
Create Infrastructure Using AWS CDK
Create GitHub Repository and personal access token
Move the Application into GitHub
Create the code for the resource stack
Upload the App to S3 Automatically
Add the Elastic Beanstalk CDK Dependencies
Create the Elastic Beanstalk Application
Create Elastic Beanstalk Application Version
Create Elastic Beanstalk Environment
Connect GitHub to CodePipelines
Build and Deploy the CDK Application
Add a Deploy Stage for Beanstalk Environment
Viewing Application Deployed in the Cloud
Update the Node.js Application Deployment
More Information and Troubleshooting
Using Multiple Versions of the CDK Libraries
We as developers want to deploy our web applications in the fastest way possible - without having to manage the underlying infrastructure. The cherry on top would be packaging both the application and infrastructure as code and running it through a continuous integration and continuous delivery (CI/CD) pipeline. That way, we could apply the same best practices of versioning, tracking changes, reviewing code, performing tests, and allowing rollbacks.
We actually can achieve this - by using AWS Elastic Beanstalk, an easy-to-use service for deploying and scaling web applications and services developed with Java, .NET, PHP, Node.js, Python, Ruby, Go, and Docker on familiar servers such as Apache, Nginx, Passenger, and IIS. We simply upload our code in a single ZIP file or a WAR file and Elastic Beanstalk automatically handles the deployment - from capacity provisioning, load balancing, auto-scaling, to application health monitoring. At the same time, we retain full control over the AWS resources powering our application and can access the underlying resources at any time.
In addition to that, we can also build the AWS Elastic Beanstalk resources using code!
The AWS Cloud Development Kit (AWS CDK) is an open-source software development framework to define cloud infrastructure in familiar programming languages and provision it through AWS CloudFormation. It consists of three major components: a core framework for modeling reusable infrastructure components, a CLI to interact with it, and a Construct Library, that has abstracted high-level components of AWS resources.
CDK Pipelines is a high-level construct library that makes it easy to set up a continuous deployment pipeline for CDK applications, powered by AWS CodePipeline.
In this guide, we will learn how to:
- Create a simple non-containerized Node.js web application
- Use AWS CDK to:
- package the web application source code
- create the deployment infrastructure (using AWS Elastic Beanstalk resources), and
- create the CI/CD pipeline (using AWS CDK Pipelines).
| About | |
|---|---|
| ✅ AWS experience | 200 - Intermediate |
| ⏱ Time to complete | 40 minutes |
| 💰 Cost to complete | Free tier eligible |
| 🧩 Prerequisites | - AWS Account and the CLI installed - AWS CDK v2.7.0 installed - GitHub account |
| 💻 Code Sample | Code sample used in tutorial on GitHub |
| 📢 Feedback | Any feedback, issues, or just a 👍 / 👎 ? |
| ⏰ Last Updated | 2023-04-10 |
Before proceeding, ensure we have following prerequisites set up and ready to use:
- An AWS account and CLI installed: If you don't already have an account, follow the Setting Up Your AWS Environment guide for a quick overview and CLI installation steps.
- CDK installed: Visit our Get Started with AWS CDK guide to learn more.
- A GitHub account: Visit GitHub.com and follow the prompts to create your account.
The first thing we need to do is create a non-containerized application that we will deploy to the cloud. For this example, we are going to use Node.js to build a web application.
The web application will be a simple web app server that will serve static HTML files and also have a REST API endpoint. The focus of this tutorial is not to teach you how to build web applications, so feel free to use the example application or build your own one. While this tutorial focuses on using Node.js, you can also build a similar web app with other Elastic Beanstalk supported programming languages (Go, Java, Node.js, PHP, Python, Ruby), application servers (Tomcat, Passenger, Puma), and Docker containers.
You can implement this in your local computer or in an AWS Cloud9 environment.
The first step is to create a new directory for our application.
Then we can initialize the Node.js project. This creates the package.json file that will contain all the definitions of our Node.js application.
If npm is not installed, install it in your local terminal following the instructions found at Setting up your Node.js development environment.
We are going to use Express as our web application framework. To use it, we need to install Express as a dependency in our Node.js project.
After running this command, we will see the dependency appear in the package.json file. Additionally, the
node_modules directory and package-lock.json files are created.Now we can create a new file called
app.js. This file will contain the business logic for where our Node.js Express server will reside.We are now ready to start adding some code. The first thing we need to add is the dependencies for the app—in this case, adding Express to allow use of the module we previously installed, and then the code to start up the web server. We will specify the web server to use port 8080, as that is what Elastic Beanstalk uses by default.
We can start up our application now, but it won't do anything yet as we have not defined any code to process requests.
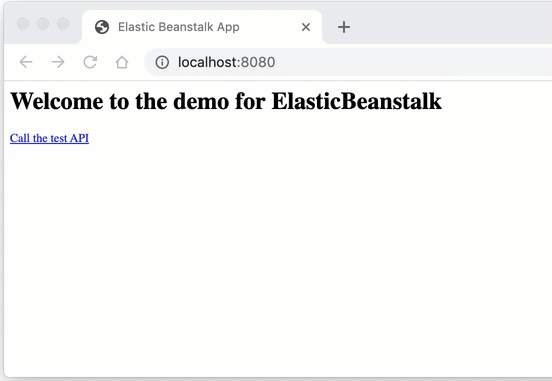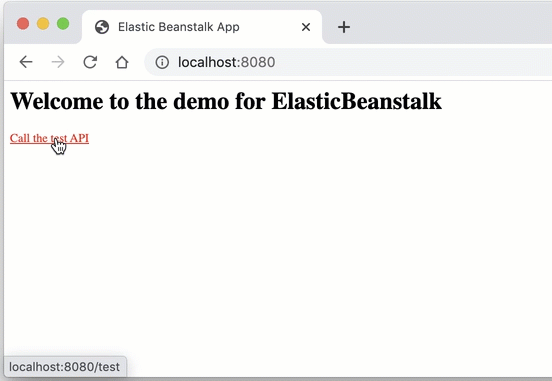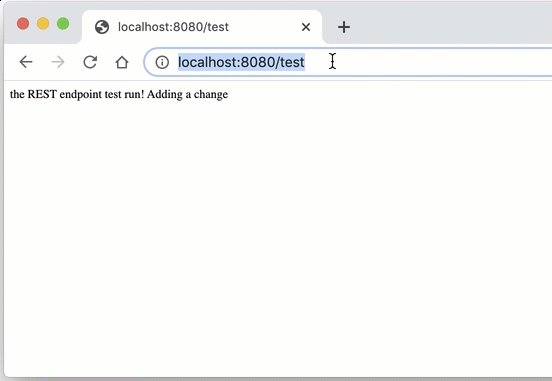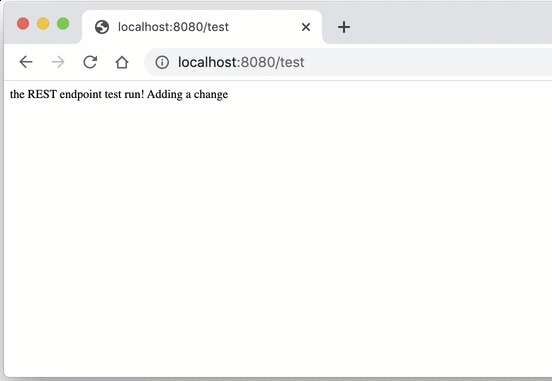
We will now add code to serve a response for a HTTP REST API call. To create our first API call, add the following code in the
app.js file:This is just to illustrate how to connect the
/test endpoint to our code; you can add in a different response, or code that does something specific.Our Express Node.js application can also serve a static web page. We need to create an HTML page to use as an example. Let's create a file called
index.html.Inside this file, add the following HTML with a link to the REST endpoint we created earlier to show how it connects to the backend:
To serve this HTML page from our Express server, we need to add some more code to render the
/path when it is called. To do this, add the following code before the /test call in app.js file:This code will serve the
index.html file whenever a request for the root of the app (/) is made.We are now ready to run our application and test if it is working locally. To do this, we are going to update
package.json with a script to make it easier to run. In the package.json file, replace the scripts section as following:Now we can go to our terminal and run:
This will start a local server with the URL
http://127.0.0.1:8080 or http://localhost:8080.When we paste this URL in our browser, we should see the following:
To stop the server, press ctrl + c to stop the process in the terminal where we ran
npm start.Now that we have our sample application, let's create a CDK application that will create all the necessary infrastructure to deploy the Node.js web app using AWS Elastic Beanstalk.
Create a repository on GitHub to store these application files. Your repository can be public or private.
If you need help, you can read the GitHub documentation on how to create a repo.
It is also a best practice to use tokens instead of passwords to access your github account via github api or command line. Read more about Creating a personal access token.
Save the token at a safe place for use later. We will be using this token for two purposes:
- Provide authentication to stage, commit, and push code from local repo to the GitHub repo. You may also use SSH keys for this.
- Connect GitHub to CodePipeline, so whenever new code is committed to GitHub repo it automatically triggers pipeline execution.
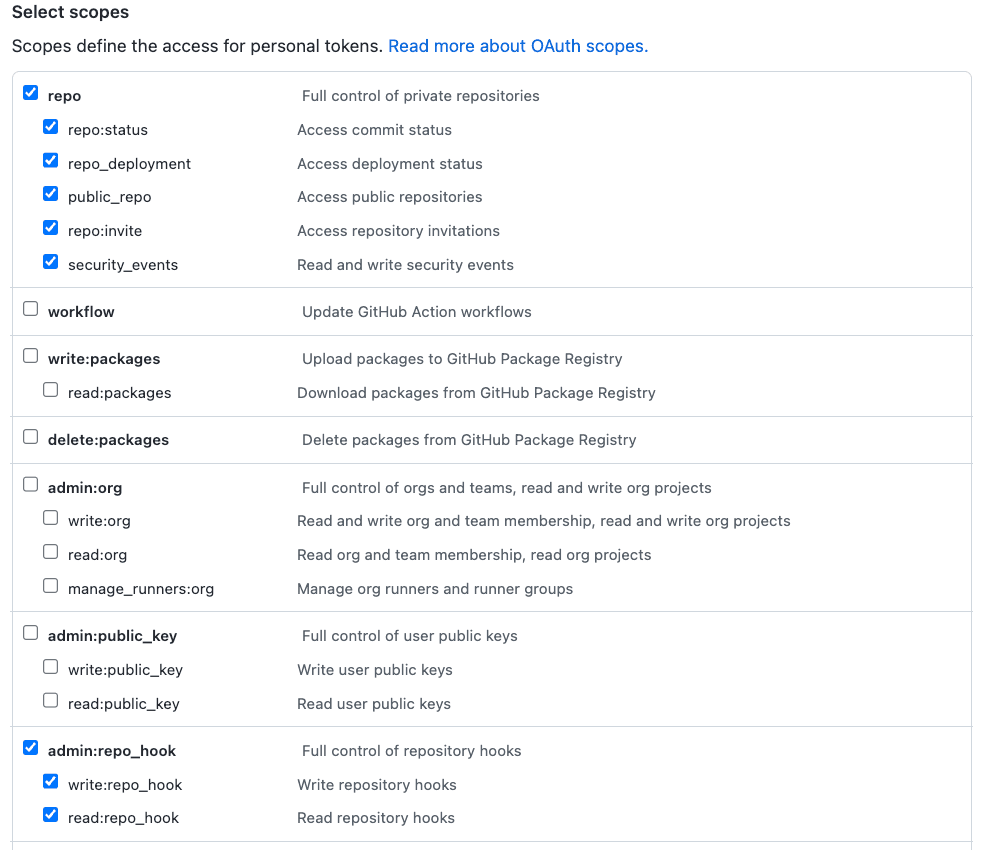
The token should have the scopes repo (to read the repository) and admin:repo_hook (if you plan to use webhooks, true by default) as shown in below image.
Create a new directory and move to that directory.
Please install the specific version of the CDK to match the dependencies that are installed later on.
Example:
Initialize the CDK application that we will use to create the infrastructure.
CDK will also initiate a local git repository. Rename the branch to main.
After the GitHub repository is created, we will push the local application files to it.
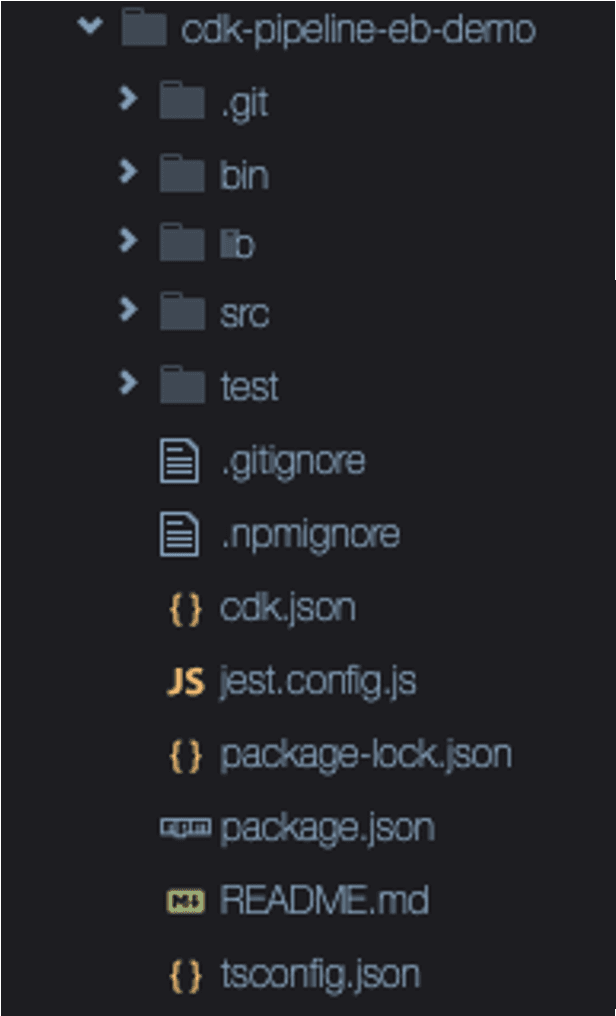
Move the application source files into new folder
src.We are also updating
.gitignore file. We are asking git to include all files from the src/* folder, except node_modules and package-lock.json. This is to ensure that every time Beanstalk deploys the application into a new virtual machine it will install the node_modules. Read more on the instructions on handling Node.js dependencies in Elastic Beanstalk packages.At this point, our folder structure should look like this:
In the following commands, we are adding all the files in current folder to stage, commit, and push it to our remote github repository. We are also caching the credentials using the Git credentials cache command.
Ensure to replace
YOUR_USERNAME with your github org and YOUR_REPOSITORY with your repository name.For the first time, it will ask you username and password for the git repo and later cache it. If you created token as recommended before, then use the token for the password prompt.
We are going to delete the default file created by CDK and define our own code for all the ElasticBeanstalk resources stack.
Simply run following code to remove the
./lib/cdk-pipeline-eb-demo.ts and create a new file ./lib/eb-appln-stack.ts.Paste following to
lib/eb-appln-stack.ts:We have defined a CDK
Stack class and a StackProps interface to accept optional stack properties. These will be referenced during initialization later.In this file
lib/eb-appln-stack.ts, we will write the code for all the resources stack we are going to create in this section. You can also copy-paste contents of this file from here.A resource stack is a set of cloud infrastructure resources—all AWS resources in this case—that will be provisioned into a specific account. The account where these resources will be provisioned is the stack that you configured in the prerequisite. In this resource stack, we are going to create these resources:
- IAM Instance profile and role: A container for an AWS Identity and Access Management (IAM) role that we can use to pass role information to an Amazon EC2 instance when the instance starts.
- S3 Assets: This helps us to upload the zipped application into Amazon Simple Storage Service (S3) and will provide the CDK application a way to get the object location.
- Elastic Beanstalk App: A logical collection of Elastic Beanstalk components, including environments, versions, and environment configurations.
- Elastic Beanstalk App Version: A specific, labeled iteration of deployable code for a web application. An application version points to an Amazon S3 object that contains the deployable code, in this case, the zip file that we will be uploading to S3 using S3 Assets. Applications can have many versions and each application version is unique.
- Elastic Beanstalk Environment: A collection of AWS resources running an application version. Each environment runs only one application version at a time.
For deploying the web app, we need to package it and upload it to Amazon S3 so that Elastic Beanstalk can deploy the application in the environment.
To do that, we will be using a CDK constructor called S3 Assets. The S3 Assets module will zip up files in the provided directory, and upload the zip to S3.
In the
lib/eb-appln-stack.ts file, add the dependency to the top of the file.Inside the stack, under the commented line that says The code that defines your stack goes here add the following code:
This code uses the S3 Assets module and takes the folder of the web app located in the root of the CDK app, compresses into a zip file and uploads it to S3. Whenever we update the application source code and push to the GitHub repo, the file will automatically get updated in S3.
Next, we will create the Elastic Beanstalk application, application version, and environment so that we can deploy the web app that we just uploaded to S3 using S3 Assets.
Add the dependency to the Elastic Beanstalk module for CDK at the top of the
lib/eb-appln-stack.ts file.Now we can create the Elastic Beanstalk app. As mentioned before, an Elastic Beanstalk application is a logical collection of Elastic Beanstalk components, like a folder.
Put this code under the code of the S3 Assets in the
lib/eb-appln-stack.ts file. This code will create the application with the name MyWebApp in Elastic Beanstalk.Now we need to create an application version from the S3 asset that we created earlier. This piece of code will create the app version using the S3 bucket name and S3 object key that S3 Assets and CDK will provide to this method.
Before moving on, we want to make sure that the Elastic Beanstalk application exists before creating the app version. We can do this with CDK by adding a dependency, as shown in the following code snippet.
To create the Elastic Beanstalk environment, we will need to provide an existing instance profile name.
An instance profile is a container for an AWS Identity and Access Management (IAM) role that we can use to pass role information to an Amazon EC2 instance when the instance starts.
In this case, the role will have attached the managed policy
AWSElasticBeanstalkWebTier, which grants permissions to the app to upload logs to Amazon S3 and debugging information to AWS X-Ray.Import the IAM module dependency in the CDK stack we have been working on:
After the code that creates the application version, add this code:
The first thing the code does is to create a new IAM role (myRole).
To allow the EC2 instances in our environment to assume the role, the instance profile specifies Amazon EC2 as a trusted entity in the trust relationship policy.
To that role we then add the managed policy
AWSElasticBeanstalkWebTier. We then create the instance profile with that role and the profile name.The last part we need to create is the Elastic Beanstalk environment. The environment is a collection of AWS resources running an application version. For the environment, we will need to give some information about the infrastructure.
Let's start by creating the environment. When creating the environment we need to give it a environment name that will appear in the Elastic Beanstalk console — in this case, we are naming the environment
MyWebAppEnvironment.Then we need to give the application name, which we will get from the Elastic Beanstalk application definition earlier.
The solution stack name is the name of the managed platform that Elastic Beanstalk provides for running web applications. Using the right solution name, Elastic Beanstalk will provision the right resources for our application, for example, the Amazon EC2 instances. We should choose the right software stack depending on the framework and platform we chose to develop our web app.
For this particular case, we are going to put this string
For this particular case, we are going to put this string
'64bit Amazon Linux 2 v5.8.0 running Node.js 18'. At the end of this blog, there is more information about solution stack names, if you are interested to know where this string came from.The option settings attribute allows us to configure the Elastic Beanstalk environment to our needs:
- IamInstanceProfile: Here we will reference the instance profile created in the previous steps.
- MinSize, MaxSize, and InstanceTypes: These are configurations for our instances and the autoscaling group that Elastic Beanstalk generates for us. These are optional parameters. If we don't set them up, Elastic Beanstalk will pick the instance type and the minimum and maximum sizes of the autoscaling group according to the platform definition. We are defining them with our own defaults so we can stay within the AWS Free Tier.
For more information about these settings, see Configuration options for Elastic Beanstalk.
To define these configuration options, add the following lines of code:
If we do not provide explicitly provide values for these options, it will consider the default values after the
??. For example, if during stack initialization we do not provide any InstanceTypes, then CDK will consider the default value t2.micro.Finally we have the version label. This is an important attribute as it needs to be a reference to the application version that we created in previous step.
With this information, we can now create our Elastic Beanstalk environment.
Here we are stating that - if no
envName property is provided during stack/stage initialization, then use the default name "MyWebAppEnvironment".Add following code in the stack definition file
lib/eb-appln-stack.ts:After we define the stack that makes up our application, we can deploy it through a CI/CD pipeline. If you want to learn more about CI/CD, check out the our DevOps Essentials guide
CDK Pipelines is a high-level construct library that makes it easy to set up a continuous deployment pipeline for our CDK applications, powered by AWS CodePipeline.
A pipeline consists of several stages, which represent logical phases of the deployment. Each stage contains one or more actions that describe what to do in that particular stage. A CDK pipeline starts with several predefined stages and actions.
For this step, we are only creating these predefined stages -
Source, Build and UpdatePipelineand hence it is an empty pipeline. In the next section, we will add stages (PublishAssets, Stage1) and actions to it to suit the needs of our application.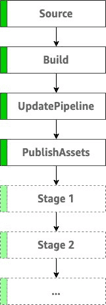
To organize things neatly, put the pipeline definition into its own stack file. Create a new file
lib/cdk-pipeline-stack.ts. Remember to replace OWNER and REPO in the code below:The code defines the following basic properties of the pipeline:
- Name for the pipeline.
- Where to find the source in GitHub. This is
Sourcestage. Every time we push new commits to this repo, the pipeline is triggered. - How to do the build and synthesis. For this use case, the
Buildstage will install latest npm packages and a standard NPM build (this type of build runsnpm run buildfollowed bynpx cdk synth).
We also need to instantiate
CdkPipelineStack with the account and AWS Region where we want to deploy the pipeline. Put the following code in bin/cdk-pipeline-eb-demo.ts. Please be sure to replace ACCOUNT and the REGION in there if necessary:CDK Pipelines use some new features of the CDK framework that we need to explicitly turn on. Add the following to our
cdk.json file in the "context" section, add a comma accordingly:When this feature flag is set to
true, CDK synthesis uses a DefaultStackSynthesizer; otherwise, a LegacyStackSynthesizer is used. CDK Pipelines deployments is supported by the DefaultStackSynthesizer. Also, the legacy template from CDK v1 is not supported in CDK v2.For AWS CodePipeline to read from this GitHub repo, we also need to configure the GitHub personal access token we created earlier.
This token should be stored as a plaintext secret (not a JSON secret) in AWS Secrets Manager under the exact name
github-token.Replace
GITHUB_ACCESS_TOKEN with your plaintext secret and REGION in following command and run it:For more help, see Creating and Retrieving a Secret.
If you are interested to use a different secret name other than the default name
github-token, there is more information at the end of this blog.If this is the first time you are using AWS CDK in this account, and in this AWS Region, you will need to bootstrap it. If you are unsure you have bootstrapped or not, run the following command. If the environment has already been bootstrapped, its bootstrap stack will be upgraded if necessary. Otherwise, nothing happens.
When deploying AWS CDK apps into an AWS account and Region, CDK needs to provision resources that it needs to perform deployments. These resources include an Amazon S3 bucket for storing the deployment files, and IAM roles that grant the needed permissions to perform deployments. Provisioning these initial resources is called bootstrapping.
To bootstrap your AWS account and Region, run the following:
npx cdk bootstrap aws://ACCOUNT-NUMBER/REGIONThis should look something like this:
npx cdk bootstrap aws://123456789012/us-east-1You can get the account number from the AWS Management Console, and the Region name from this list.
The required resources are defined in an AWS CloudFormation stack, called the bootstrap stack, which is usually named
CDKToolkit and you can find it in the CloudFormation console.After we have bootstrapped our AWS account and Region, we are ready to build and deploy our CDK application.
The first step is to build the CDK application.
If there are no errors in our application, this will succeed. We can now push all the code to the GitHub repository.
We can now deploy the CDK application in the cloud.
Please note, the pipeline created by CDK pipelines is self-mutating. This means we only need to run
cdk deploy one time to get the pipeline started. After that, the pipeline will automatically update itself, when we add the new stage (or CDK applications) in the source code.So, as a one-time operation, deploy the pipeline stack:
Because we created a new role, we will be asked to confirm changes in our account security level. Please note, the resource changes list will be longer than shown in the following image. This is for representation purposes only.
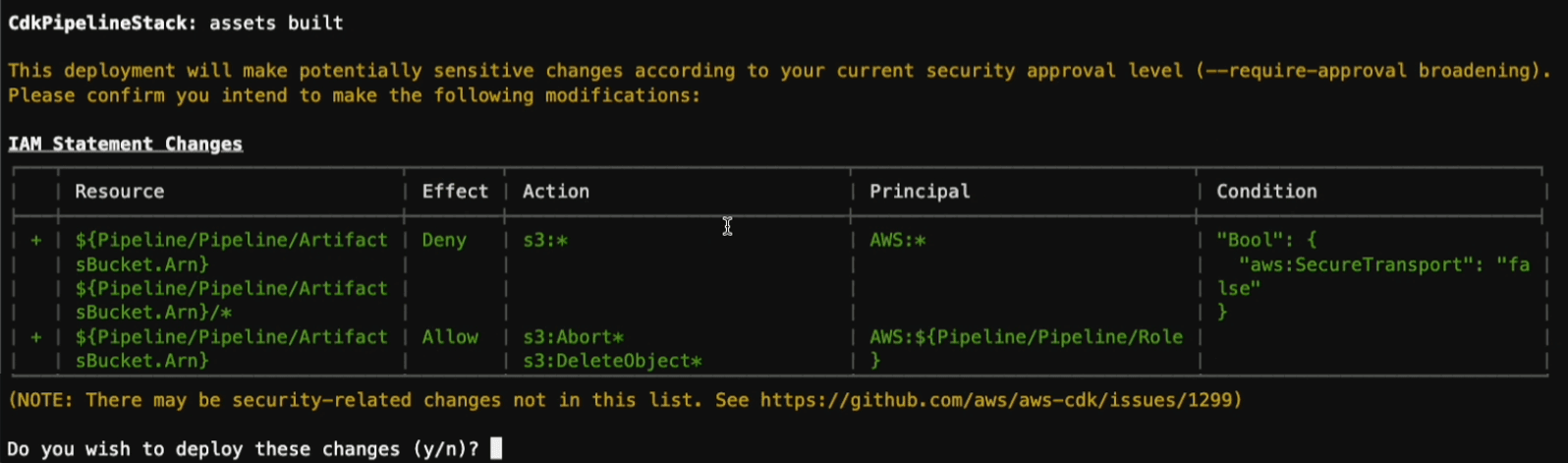
Respond with y, and then the deployment will start. It takes a few minutes to complete. When it is done, we will receive a message containing the ARN (Amazon Resource Name) of the CloudFormation stack that this deployment created for us.
Open the CloudFormation Management console, to see the new CloudFormation stack.

This take a couple of minutes to finish. At the end, we can find a pipeline in our CodePipeline console, as in the following screenshot.
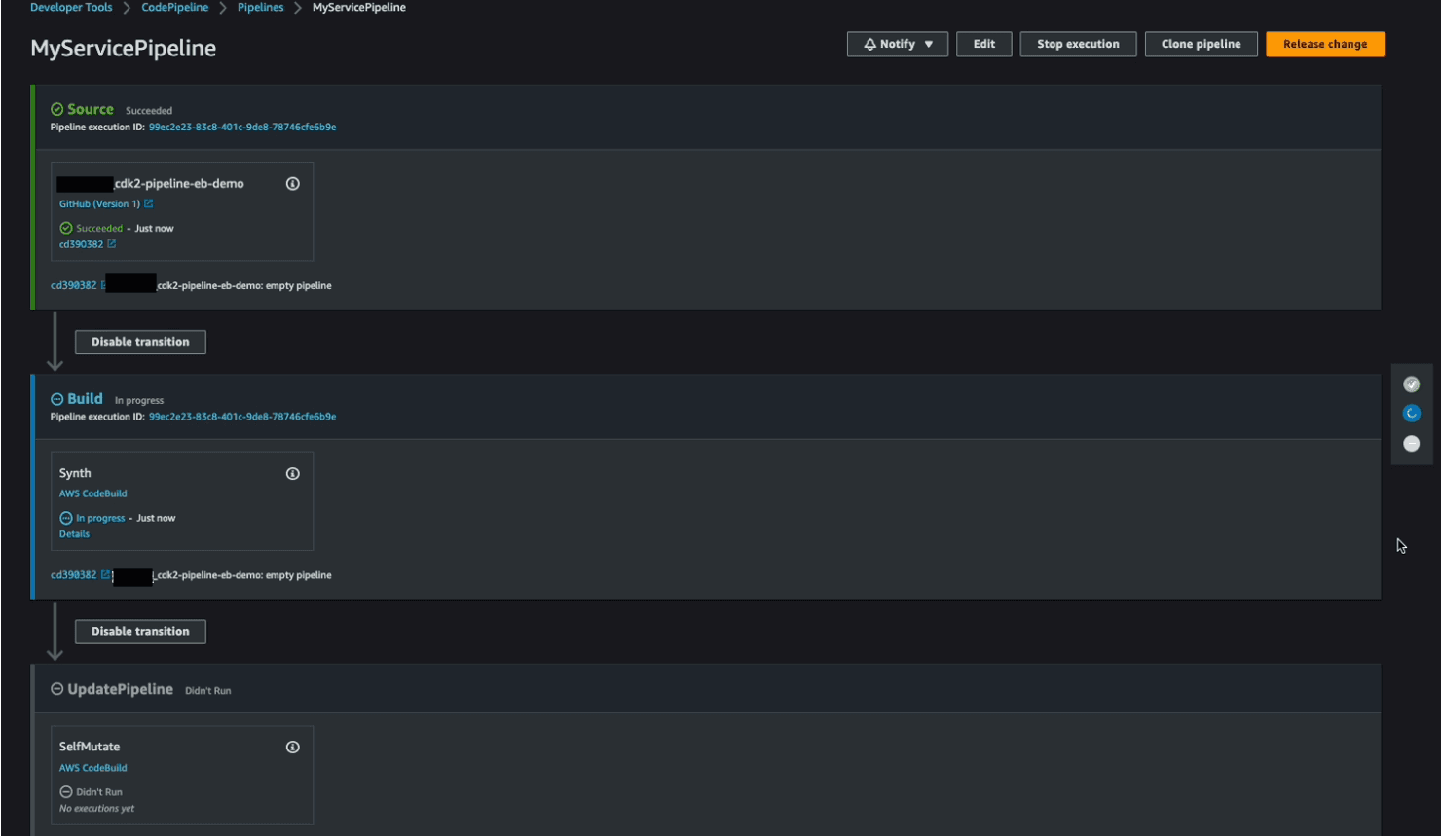
Troubleshooting tip: if you see an Internal Failure error during this step while the pipeline is being created, double check you have a Secrets Manager secret with the right name configured with your GitHub token in it as mentioned in the previous section.
So far, we have provisioned an empty pipeline, and the pipeline isn’t deploying our web application yet.
The first step is to define our own subclass of stage, which describes a single logical, cohesive deployable unit of our application. This is similar to how we define custom subclasses of Stack to describe CloudFormation stacks. The difference is that a Stage can contain one or more Stacks, so it gives us the flexibility to make multiple copies of our potentially complex application via the pipeline. For this use case, our stage consists of only one stack.
Create a new file
lib/eb-stage.ts and put the following code in it:Now, add instances of our
CdkEBStage to the pipeline.Add a new import line at the top of
lib/cdk-pipeline-stack.ts:and following code after the mentioned comment:
Here, we are providing custom values for the
minSize, and maxSize. We are using the default instanceTypes and environment name defined in the CDK stack. If you want to add another stage to the pipeline, make sure to add a custom value for envName to differentiate the Beanstalk environments.All we have to do now is to commit and push this, and the pipeline will automatically reconfigures itself to add the new stage and deploy to it. Let's run
npm run build first to make sure there are no typos.Run the following commands to do so:
In CodePipeline console, once the UpdatePipeline stage picks up new code for an additional stage, it will self-mutate and add 2 new stages, one for the
Assets and another for Pre-Prod.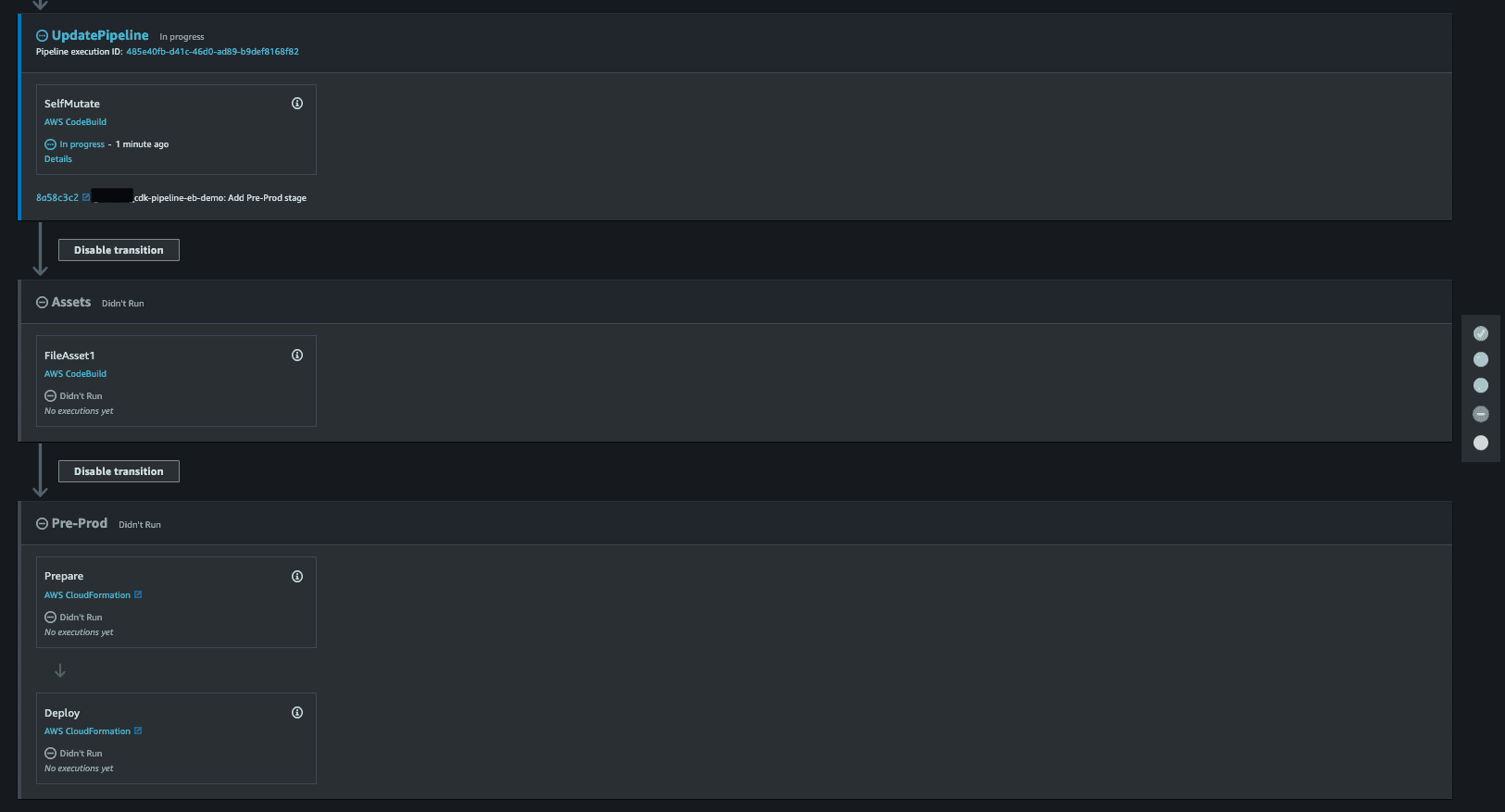
Once the
UpdatePipeline stage has completed successfully, the pipeline will again run from start. This time it will not stop at UpdatePipeline stage. It will transition further to the new stages Assets and Pre-prod to deploy the Beanstalk application, environment and the my_webapp application.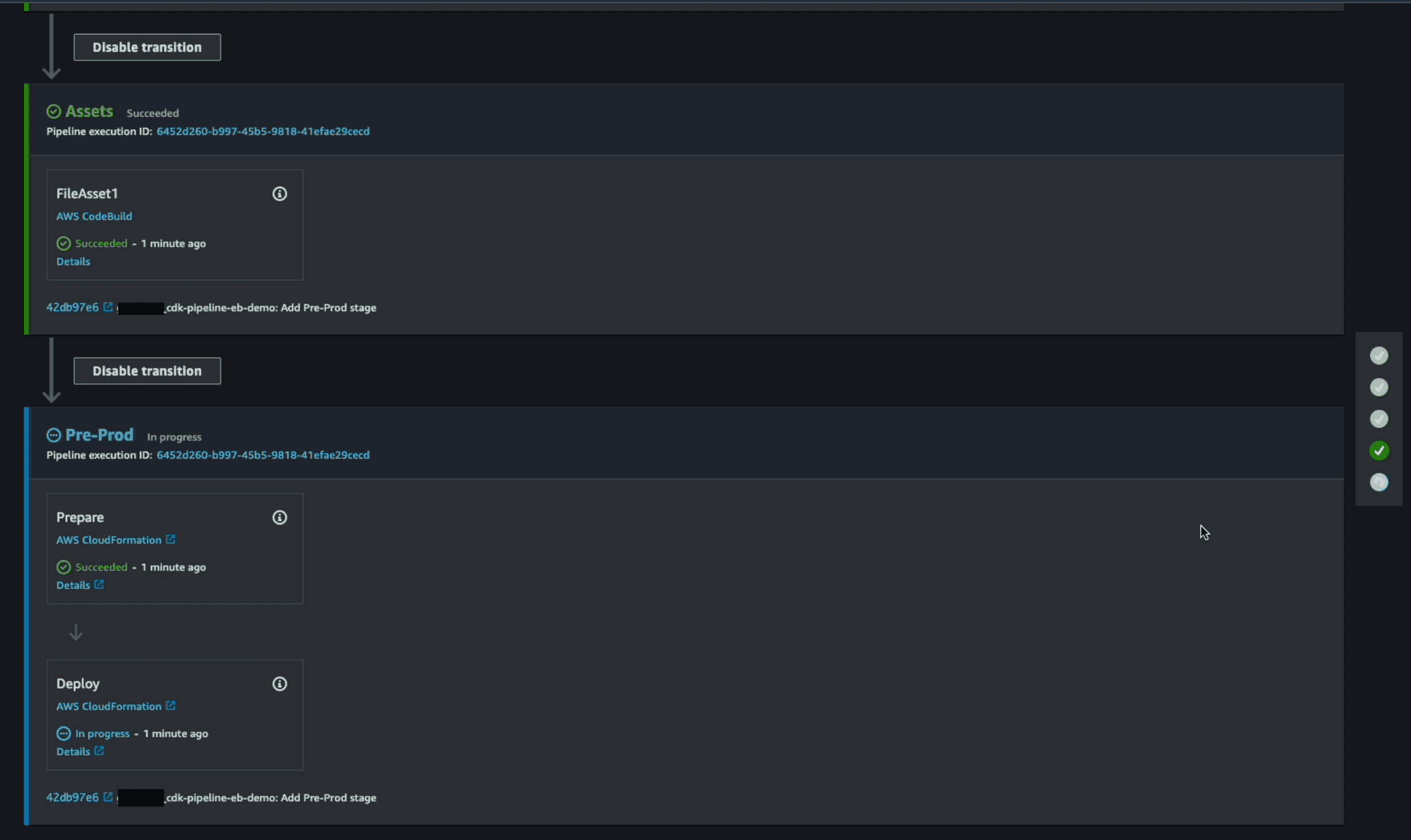
We can find 2 new CloudFormation stacks from the
Pre-Prod stage in the CloudFormation console.
The stack called
Pre-Prod-WebService contains all the Elastic Beanstalk resources we created in the previous module: Elastic Beanstalk application, application version, instance profile, and environment.The other stack (with the random string
awseb-e-randomstring-stack), which was created by Elastic Beanstalk, contains all the resources the Elastic Beanstalk app needs to run—autoscaling groups, instances, Amazon CloudWatch alarms and metrics, load balancers, and security groups.After the pipeline finishes running through the final
Pre-Prod stage, we can confirm that the service is up and running.We can find this URL by going to the Elastic Beanstalk service in the AWS Management Console, and look for the environment called
MyWebAppEnvironment. Choose the URL to launch the web app.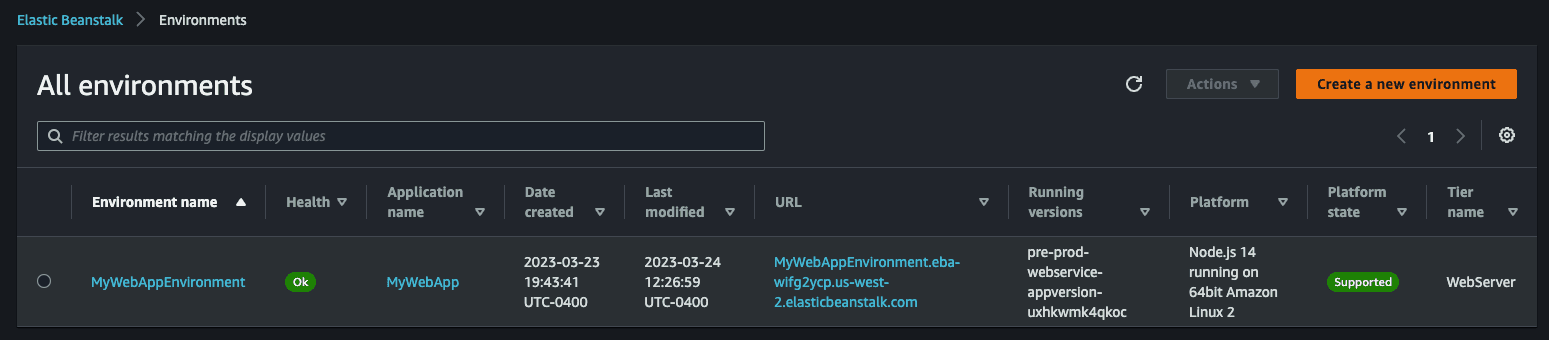
The application should now be available to be accessed from anywhere.
If we want to make a change to our web application, and redeploy it to the cloud, follow these steps:
- Make the changes in the web app
- Stage, Commit, and Push the changes to GitHub repo.
That's it!
CodePipeline will be triggered as soon as the code is pushed to the GitHub repo. It will automatically run the code through the entire pipeline and deploy the new application version to our ElasticBeanstalk environment. This takes a bit of time.
Once the
Pre-prod stage of CodePipeline has completed successfully, we can verify that there is a new version of the Elastic Beanstalk app deployed. Simply refresh the application URL in the browser to see the deployed changes.The benefit of using AWS CDK and CloudFormation for all infrastructure is that cleaning up AWS environment is easy.
Run the following command inside the CDK application directory:
Run the following command inside the CDK application directory:
We can verify the
CdkPipelineStack stack was deleted by going to the AWS CloudFormation Management Console.However, please note this will only destroy resources created by cdk when we run the
cdk deploy command. It will not destroy the 2 CloudFormation stacks that were deployed by the Pre-Prod stage.We have to delete the
Pre-Prod-WebService manually from the CloudFormation Console or using following command:If the stack delete fails with the error
Cannot delete entity, must detach all policies first. Then delete the IAM role (name starts with Pre-Prod-WebService-MyWebAppawselasticbeanstalkec2-randomstring) manually from IAM Console and retry deleting the CloudFormation stack. For help, read Deleting roles or instance profiles in the AWS Documentation.Goto CloudFormation Console, check if all the three stacks that were created are deleted successfully. You could optionally delete the CloudFormation stack named
CDKToolkit created during bootstrap.Finally, CDK Pipelines create an Amazon S3 bucket to store artifacts. This bucket is retained even after stack deletion. Empty and delete the bucket that starts with
cdkpipelinestack-pipelineartifactsbucket<random-letters>. For more information, read S3 documentation to Emptying and Deleting a bucket.Congratulations! We have now learned how to deploy a non-containerized application in the cloud. We created a simple Node.js web application, and then we used AWS CDK to create deployment infrastructure(using AWS Elastic Beanstalk resources) and the CI/CD pipeline (using AWS CDK Pipelines). If you enjoyed this tutorial, found any issues, or have feedback for us, please send it our way!
For more DevOps related content, check out How Amazon Does DevOps in Real Life.
One common error you might get when using CDK is that when you import a library and start using it in your application, the word "this" gets highlighted and you receive a compilation error.

This might happen because you are using CDK module with a different version than the CDK core library. CDK updates happen often, so it's a common error.
To fix this, you need to update all the CDK packages to the same version. You can see the version of your CDK packages in the
package.json file in your CDK application.In the documentation, you can read about all the supported platforms for Elastic Beanstalk. We update this page as newer platforms are added and older platforms get retired.
If you are curious about how to get the right platform name, such as
64bit Amazon Linux 2 v5.8.0 running Node.js 18, you can use the AWS CLI to get a list of all the supported platforms.This returns a long list of supported platforms strings that you can use in your CDK application.
If your pipeline creation is failing with error
Access Denied to source code GitHub repository, then you do not have a secret with name github-token, which is the default value in CDK.If you have token in a different name, e.g.
github-access-token-secret, you have to update the CDK code in lib/cdk-pipeline-stack.ts. Import cdk and add authentication with secret name using following code:Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.